Importance of vmstat command :
The first tool to use is the vmstat command, which quickly provides compact information about various system resources and their related performance problems.
The vmstat command reports statistics about kernel threads in the run and wait queue, memory, paging, disks, interrupts, system calls, context switches, and CPU activity. The reported CPU activity is a percentage breakdown of user mode, system mode, idle time, and waits for disk I/O.
Note: If the vmstat command is used without any interval, then it generates a single report. The single report is an average report from when the system was started. You can specify only the Count parameter with the Interval parameter. If theInterval parameter is specified without the Count parameter, then the reports are generated continuously.
As a CPU monitor, the vmstat command is superior to the iostat command in that its one-line-per-report output is easier to scan as it scrolls and there is less overhead involved if there are many disks attached to the system. The following example can help you identify situations in which a program has run away or is too CPU-intensive to run in a multiuser environment.
This output shows the effect of introducing a program in a tight loop to a busy multiuser system. The first three reports (the summary has been removed) show the system balanced at 50-55 percent user, 30-35 percent system, and 10-15 percent I/O wait. When the looping program begins, all available CPU cycles are consumed. Because the looping program does no I/O, it can absorb all of the cycles previously unused because of I/O wait. Worse, it represents a process that is always ready to take over the CPU when a useful process relinquishes it. Because the looping program has a priority equal to that of all other foreground processes, it will not necessarily have to give up the CPU when another process becomes dispatchable. The program runs for about 10 seconds (five reports), and then the activity reported by the vmstat command returns to a more normal pattern.
Optimum use would have the CPU working 100 percent of the time. This holds true in the case of a single-user system with no need to share the CPU. Generally, if us +sy time is below 90 percent, a single-user system is not considered CPU constrained. However, if us + sy time on a multiuser system exceeds 80 percent, the processes may spend time waiting in the run queue. Response time and throughput might suffer.
To check if the CPU is the bottleneck, consider the four cpu columns and the twokthr (kernel threads) columns in the vmstat report. It may also be worthwhile looking at the faults column:
cpu
Percentage breakdown of CPU time usage during the interval. The cpucolumns are as follows:
us:The us column shows the percent of CPU time spent in user mode. A UNIX process can execute in either user mode or system (kernel) mode. When in user mode, a process executes within its application code and does not require kernel resources to perform computations, manage memory, or set variables.
sy:The sy column details the percentage of time the CPU was executing a process in system mode. This includes CPU resource consumed by kernel processes (kprocs) and others that need access to kernel resources. If a process needs kernel resources, it must execute a system call and is thereby switched to system mode to make that resource available. For example, reading or writing of a file requires kernel resources to open the file, seek a specific location, and read or write data, unless memory mapped files are used.
The first tool to use is the vmstat command, which quickly provides compact information about various system resources and their related performance problems.
kthr memory page faults cpu
----- ----------- ------------------------ ------------ -----------
r b avm fre re pi po fr sr cy in sy cs us sy id wa
1 0 22478 1677 0 0 0 0 0 0 188 1380 157 57 32 0 10
1 0 22506 1609 0 0 0 0 0 0 214 1476 186 48 37 0 16
0 0 22498 1582 0 0 0 0 0 0 248 1470 226 55 36 0 9
2 0 22534 1465 0 0 0 0 0 0 238 903 239 77 23 0 0
2 0 22534 1445 0 0 0 0 0 0 209 1142 205 72 28 0 0
2 0 22534 1426 0 0 0 0 0 0 189 1220 212 74 26 0 0
3 0 22534 1410 0 0 0 0 0 0 255 1704 268 70 30 0 0
2 1 22557 1365 0 0 0 0 0 0 383 977 216 72 28 0 0
2 0 22541 1356 0 0 0 0 0 0 237 1418 209 63 33 0 4
1 0 22524 1350 0 0 0 0 0 0 241 1348 179 52 32 0 16
1 0 22546 1293 0 0 0 0 0 0 217 1473 180 51 35 0 14
Note: If the vmstat command is used without any interval, then it generates a single report. The single report is an average report from when the system was started. You can specify only the Count parameter with the Interval parameter. If theInterval parameter is specified without the Count parameter, then the reports are generated continuously.
As a CPU monitor, the vmstat command is superior to the iostat command in that its one-line-per-report output is easier to scan as it scrolls and there is less overhead involved if there are many disks attached to the system. The following example can help you identify situations in which a program has run away or is too CPU-intensive to run in a multiuser environment.
Optimum use would have the CPU working 100 percent of the time. This holds true in the case of a single-user system with no need to share the CPU. Generally, if us +sy time is below 90 percent, a single-user system is not considered CPU constrained. However, if us + sy time on a multiuser system exceeds 80 percent, the processes may spend time waiting in the run queue. Response time and throughput might suffer.
To check if the CPU is the bottleneck, consider the four cpu columns and the twokthr (kernel threads) columns in the vmstat report. It may also be worthwhile looking at the faults column:
cpu
Percentage breakdown of CPU time usage during the interval. The cpucolumns are as follows:
us:The us column shows the percent of CPU time spent in user mode. A UNIX process can execute in either user mode or system (kernel) mode. When in user mode, a process executes within its application code and does not require kernel resources to perform computations, manage memory, or set variables.
sy:The sy column details the percentage of time the CPU was executing a process in system mode. This includes CPU resource consumed by kernel processes (kprocs) and others that need access to kernel resources. If a process needs kernel resources, it must execute a system call and is thereby switched to system mode to make that resource available. For example, reading or writing of a file requires kernel resources to open the file, seek a specific location, and read or write data, unless memory mapped files are used.
id:The id column shows the percentage of time which the CPU is idle, or waiting, without pending local disk I/O. If there are no threads available for execution (the run queue is empty), the system dispatches a thread called wait, which is also known as the idle kproc. On an SMP system, onewait thread per processor can be dispatched. The report generated by the ps-k or -g 0 option) identifies this askproc or wait. If the ps report shows a high aggregate time for this thread, it means there were significant periods of time when no other thread was ready to run or waiting to be executed on the CPU. The system was therefore mostlyidle and waiting for new tasks. command (with the
wa:The wa column details the percentage of time the CPU wasidle with pending local disk I/O and NFS-mounted disks. If there is at least one outstanding I/O to a disk when wait is running, the time is classified as waiting for I/O. Unless asynchronous I/O is being used by the process, an I/O request to disk causes the calling process to block (or sleep) until the request has been completed. Once an I/O request for a process completes, it is placed on the run queue. If the I/Os were completing faster, more CPU time could be used.
A wa value over 25 percent could indicate that the disk subsystem might not be balanced properly, or it might be the result of a disk-intensive workload.
Number of kernel threads in various queues averaged per second over the sampling interval. The kthr columns are as follows:
r:Average number of kernel threads that are runnable, which includes threads that are running and threads that are waiting for the CPU. If this number is greater than the number of CPUs, there is at least one thread waiting for a CPU and the more threads there are waiting for CPUs, the greater the likelihood of a performance impact.
b:Average number of kernel threads in the VMM wait queue per second. This includes threads that are waiting on filesystem I/O or threads that have been suspended due to memory load control.
If processes are suspended due to memory load control, the blocked column (b) in the vmstat report indicates the increase in the number of threads rather than the run queue.
p:For vmstat -I The number of threads waiting on I/Os to raw devices per second. Threads waiting on I/Os to filesystems would not be included here.
faults
Information about process control, such as trap and interrupt rate. Thefaults columns are as follows:
in:Number of device interrupts per second observed in the interval. Additional information can be found in Assessing disk performance with the vmstat command.
A wa value over 25 percent could indicate that the disk subsystem might not be balanced properly, or it might be the result of a disk-intensive workload.
Number of kernel threads in various queues averaged per second over the sampling interval. The kthr columns are as follows:
r:Average number of kernel threads that are runnable, which includes threads that are running and threads that are waiting for the CPU. If this number is greater than the number of CPUs, there is at least one thread waiting for a CPU and the more threads there are waiting for CPUs, the greater the likelihood of a performance impact.
b:Average number of kernel threads in the VMM wait queue per second. This includes threads that are waiting on filesystem I/O or threads that have been suspended due to memory load control.
If processes are suspended due to memory load control, the blocked column (b) in the vmstat report indicates the increase in the number of threads rather than the run queue.
p:For vmstat -I The number of threads waiting on I/Os to raw devices per second. Threads waiting on I/Os to filesystems would not be included here.
faults
Information about process control, such as trap and interrupt rate. Thefaults columns are as follows:
in:Number of device interrupts per second observed in the interval. Additional information can be found in Assessing disk performance with the vmstat command.
sy:The number of system calls per second observed in the interval. Resources are available to user processes through well-defined system calls. These calls instruct the kernel to perform operations for the calling process and exchange data between the kernel and the process. Because workloads and applications vary widely, and different calls perform different functions, it is impossible to define how many system calls per-second are too many. But typically, when the sy column raises over 10000 calls per second on a uniprocessor, further investigations is called for (on an SMP system the number is 10000 calls per second per processor). One reason could be "polling" subroutines like the select() subroutine. For this column, it is advisable to have a baseline measurement that gives a count for a normal sy value.
cs:Number of context switches per second observed in the interval. The physical CPU resource is subdivided into logical time slices of 10 milliseconds each. Assuming a thread is scheduled for execution, it will run until its time slice expires, until it is preempted, or until it voluntarily gives up control of the CPU. When another thread is given control of the CPU, the context or working environment of the previous thread must be saved and the context of the current thread must be loaded. The operating system has a very efficient context switching procedure, so each switch is inexpensive in terms of resources. Any significant increase in context switches, such as when cs is a lot higher than the disk I/O and network packet rate, should be cause for further investigation
 Fig: Java Visual VM
Fig: Java Visual VM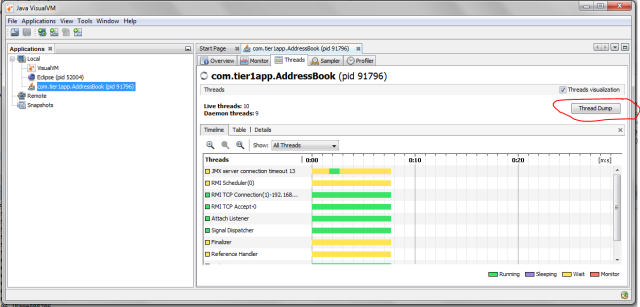
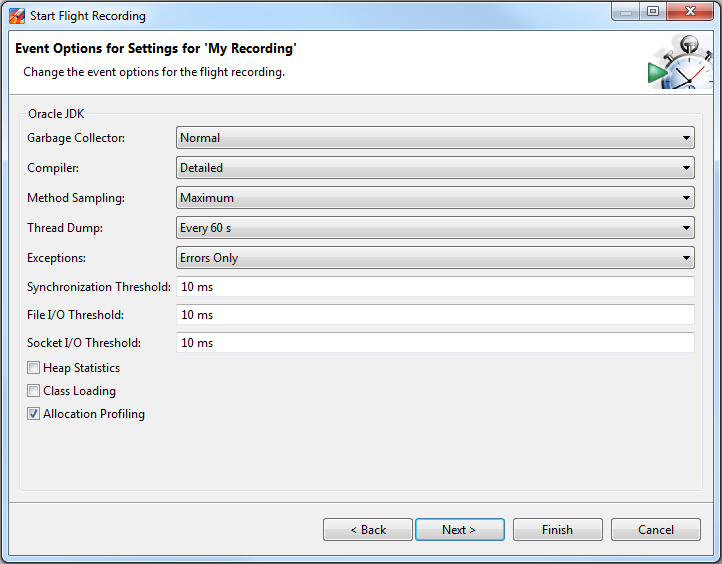 Fig: Flight Recorder wizard showing ‘Thread Dump’ capture option.
Fig: Flight Recorder wizard showing ‘Thread Dump’ capture option.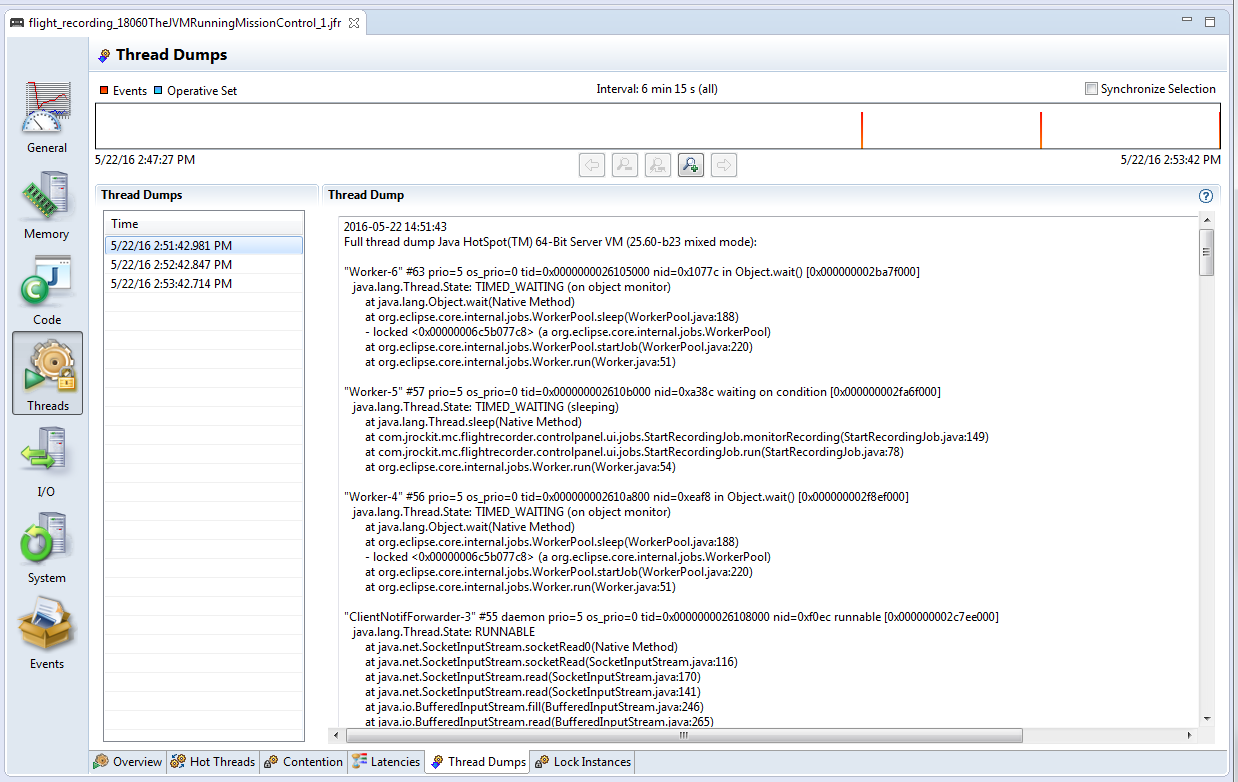
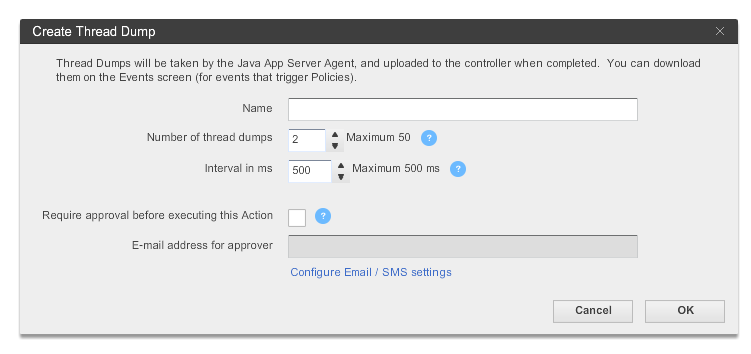












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}